Inspiration
I did some research on the net and mainly used
Jonathan Hodgson's post on codeproject.com, dating from june 2004, that describes the Squarified treemap technique.
The Squarified treemap algorithm is explained in
an academic paper related to Human Computer Interaction (HCI) by
Ben Shneiderman of the University of Maryland.
You can find
here his excellent explanation that I followed to write this User Defined Function for Excel.
A great Treemap summary post on
Juice Analytics' blog also helped me to provide the right features.
Parameters
First of all, remember that your data
must be sorted with highest values at the top of the column (I know, this could easily be integrated in the UDF... sometime maybe).
The syntax of the UDF is :
TREEMAP(DataRange, DestinationRange, HeightPixel, WidthPixel, ColorRange, ColorScale, LabelRange, TooltipRange, HighlightPosition).
Only
DataRange and
DestinationRange are compulsory parameters. Others are optionals.
Lets describe each parameter :
- DataRange : Range of data containing the values used for the Size of the sectors. Must be 1 column by X rows.
As clearly explained on
Juice Analytics blog : "
Size of the boxes should be a quantity measure.
The measures should sum up along the hierarchical structure of the data.
The sum of all the elements in one branch need to sum to the value of the branch as a whole.
Therefore, you can’t use ratios or dates or any other measure you wouldn’t use in a pie chart."
- DestinationRange : Range of cells that will contain the Treemap or 1 single cell...
If DestinationRange is a single cell, we have 2 cases with the following parameters :
- HeightPixel or WidthPixel are not specified or both = 0 :
Treemap will be displayed inside this unique cell (you should better make it big, or merge several cells)
- HeightPixel AND WidthPixel are specified (integer number, lets say between 100 and 500):
Treemap will be displayed inside a rectangle of corresponding height and width (in Pixel or points, I am not sure).
This is especially important when comparing 2 Treemaps and you want to have exact proportionnality of their respective total surface (lets say representing my stock portfolio's value before and after the crisis... just a painful example).
- ColorRange : contains the data (number or text !) used to define Color of the individual sectors. If this parameter is left blank, all sectors will be grey... clear and simple (Hi
Robert !)
Again
Juice Analytics : "
Color of the boxes is best suited to a measure of performance or change such as growth over time, average conversion rate, or customer satisfaction."
Color can also be used to identify categories.
ColorRange
must have the same size as DataRange : One color per sector, so logically organize your data in identically sized columns.
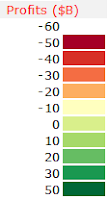 - ColorScale
- ColorScale : No flexibility here. This has to be a range of 2 columns by Y rows, like for the
Heatmap() UDF.
The first columns contains intervals or categories, in line with the values of the ColorRange area.
In front of each interval value, the 2nd column contains the RBG color code that will fill the sectors.
Color codes are available
here and from
Cynthia Brewer's
ColorBrewer.
The color scale must be organized so that the lowest value is at the top, like in the screenshot from the previous post.
- LabelRange : Staightforward, range of cells (same size as DataRange again), containing the text for labels to be applyed to each sector.
I tried to maximize the size of the text inside the sector, like for tag-clouds, it emphasises the importance of big sectors in the treemap.
Labels will be displayed in black or in white, always maximizing the contrast against the background sector color.
- ToolTipRange : same as LabeRange, but this text will be displayed in a floating tooltip when hovering the mouse over the treemap.
Defenitely usefull to provide more detailed information than the label could.
- HighlightPosition : Integer number. Basically, it's the rank in the data range of the sector that you want to highlight. A red frame will be displayed around the corresponding sector... long to explain, easy to understand if you have come so far (Hopefuly!)
Regarding the VBA code.
1) it works reasonnably well. I tested it with 1 500 sectors with no trouble and great resolution in the smallest sectors
2) it is damn slow due to numerous iterations and loops, that could certainly be avoided by using collection or dictionnary objects instead of arrays.
3) Unlike C#, Silverlight or Java implementations, this code is not recursive... might be a reason why it's soooo slow.
Actually, this UDF is not a Treemap, rather a Branchmap... A treemap would have a fractal structure, with each sector including at least one embeded treemap, like real tree-trunk with branches and leaves.
I you are interested to go further with Treemap, specific Treemaping softwares are listed
here and more information available from the
University of Maryland.
Last and not least.
The permantly-beta version of the add-in is available
here (for XL2007 only)
An example file is available
here.
Now you can create an interactive version of this nice
Treemap from the NY Times... with Excel !
Felices fiestas !












{kind=link}